 第17期 - Meta 发布Llama 3
第17期 - Meta 发布Llama 3

在内部讲话中,李彦宏对大模型开源与闭源的路线选择,以及 AI 创业者应该专注模型还是应用等业界焦点话题,发表了自己的看法。
Ai周刊:关注 Python、机器学习、深度学习、大模型等硬核技术
本期目录: [toc]
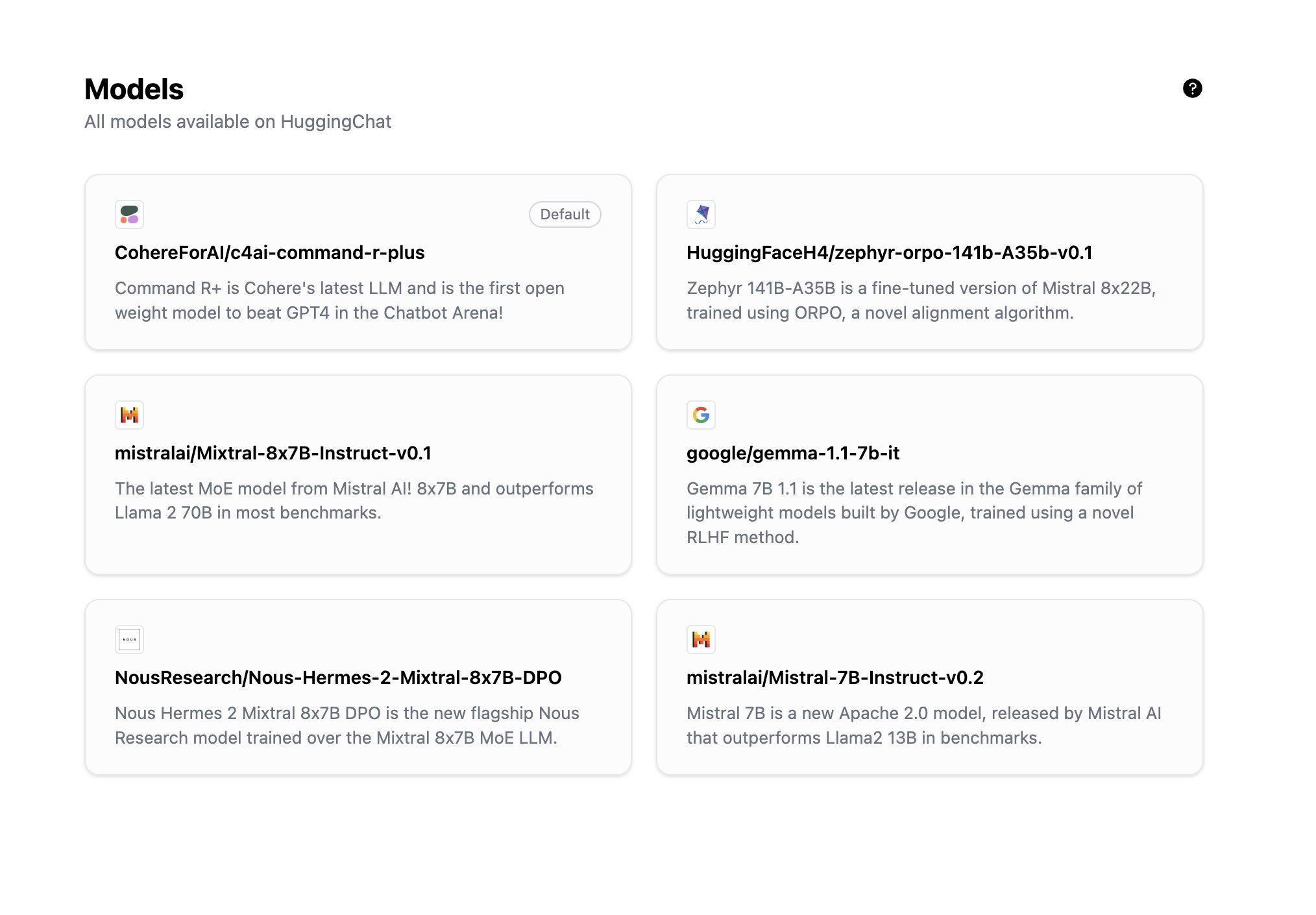
1、Meta 最新发布 Llama 3 80 亿和 700 亿参数版本
Meta 官方数据显示,Llama 3 8B 和 70B 版本在语言(MMLU)、知识(GPQA)、编程(HumanEval)、数学(GSM-8K、MATH)等能力上,Llama 3 几乎全面领先于同等规模的其他模型。
8B 模型在 MMLU、GPQA、HumanEval 等多项基准上均胜过 Gemma 7B 和 Mistral 7B Instruct。
而 70B 模型则超越了闭源的当红炸子鸡 Claude 3 Sonnet,和谷歌的 Gemini Pro 1.5 打得有来有回。
目前,Llama 3 两种参数量的基础和 Instruct 版本都已上线 Hugging Face 可供下载。
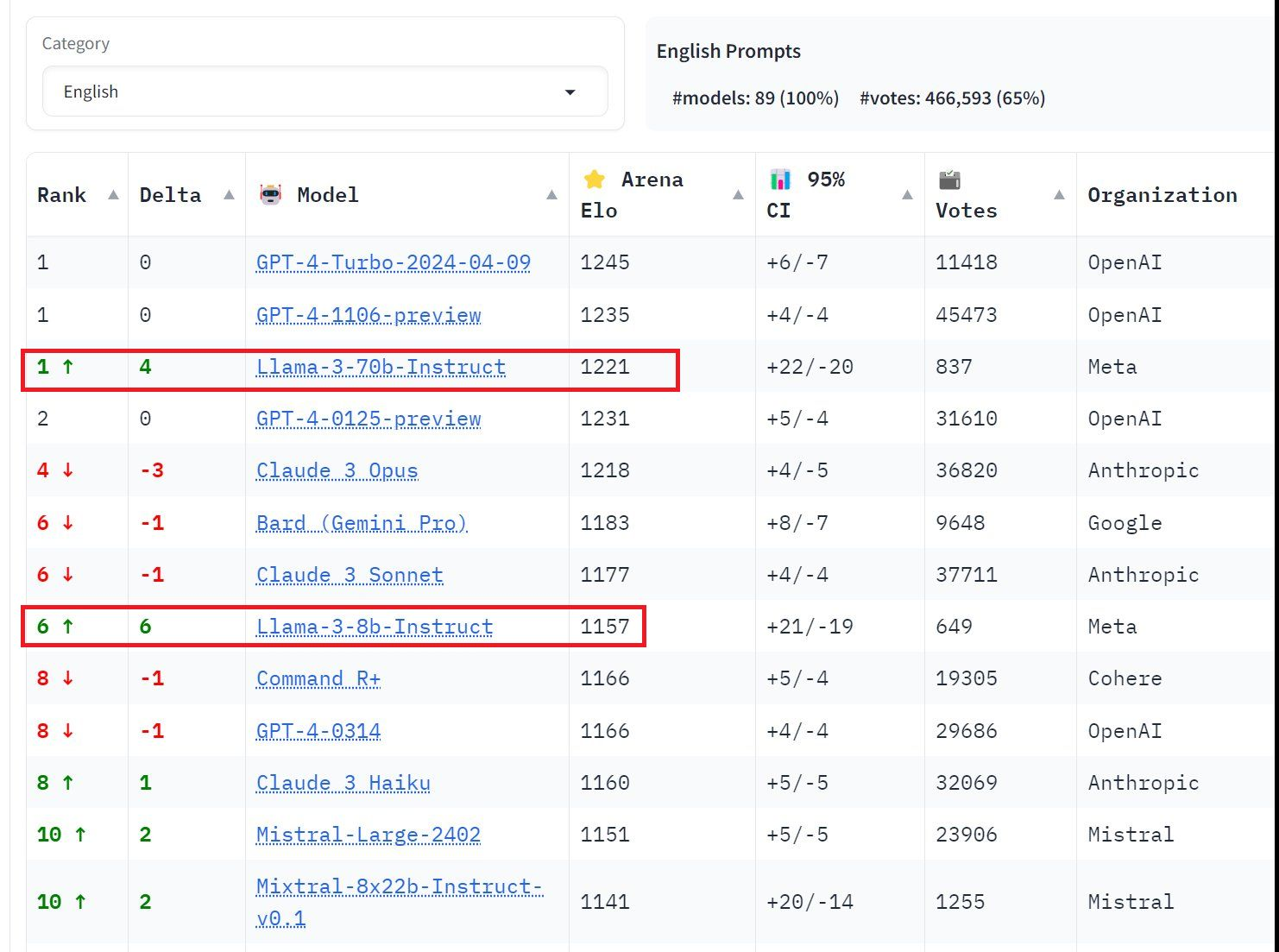
2、「抱抱脸」公司的免费对话服务现在提供六种模型
「抱抱脸」公司的免费对话服务现在提供六种模型,包括 Command R+、基于 Mixtral-8x22B 模型的调参版本
网址:https://huggingface.co/chat/models
3、数据分析:900 个最受欢迎的开源 AI 工具
原文:https://huyenchip.com/2024/03/14/ai-oss.html
这篇文章分析了 900 个最受欢迎的开源 AI 工具,重点关注了基于基础模型的栈。
- 作者使用关键词 gpt、llm 和 generative ai 在 GitHub 上进行搜索。
- 限制搜索结果为至少有 500 星标的仓库,共计找到 845 个软件仓库。
- 包括教程和聚合列表在内的 896 个仓库。
新 AI 技术栈
- 基础设施: 包括服务工具(如 vllm、NVIDIA 的 Triton)、计算管理(如 skypilot)、向量搜索和数据库(如 faiss、milvus、qdrant、lancedb)等。
- 模型开发: 提供开发模型的工具,包括建模和训练框架(如 transformers、pytorch、DeepSpeed)、推理优化、数据集工程、评估等。
- 应用开发: 基于现有模型开发应用程序,也称为 AI 工程。
- 应用程序: 在现有模型基础上构建的开源应用程序,如编码、工作流自动化、信息聚合等。
- 模型仓库: 由公司和研究人员创建,用于共享与其模型相关的代码,如 CompVis/stable-diffusion、openai/whisper、facebookresearch/llama。
-
AI 堆栈的演变:2023 年见证了新工具的爆炸性增长,特别是在 Stable Diffusion 和 ChatGPT 引入之后。然而,从 2023 年 9 月开始,增长曲线趋于平稳,可能的原因包括:低挂果实已被摘取、生成 AI 领域的竞争加剧以及人们对生成 AI 的兴趣有所降温。
-
开源 AI 开发者:开源软件遵循长尾分布,少数账户控制着大部分仓库。文章提到,有 20 个账户至少有 4 个仓库,这些账户托管了 195 个仓库,占列表中所有仓库的 23%。
-
中国的开源生态系统:中国的 AI 生态系统与美国有所不同,GitHub 在中国的流行 AI 仓库中占有一席之地,许多仓库的描述是用中文写的。
-
快速增长和快速衰退的模式:作者观察到一种模式,即许多仓库迅速获得大量关注,然后迅速沉寂。这种现象被称为“炒作曲线”。
4、李彦宏内部讲话曝光:开源模型会越来越落后
在内部讲话中,李彦宏对大模型开源与闭源的路线选择,以及 AI 创业者应该专注模型还是应用等业界焦点话题,发表了自己的看法。
不过李彦宏的观点受到行业内一众大佬和网友的嘲讽,认为李彦宏最近几年的何种判断都严重失误。
以下是李彦宏的几个核心论断。
1、闭源模型在能力上会持续地领先,而不是一时地领先。
2、模型开源也不是一个众人拾柴火焰高的情况,这跟传统的软件开源一比如 Linux、安卓等等很不一样。
3、闭源是有真正的商业模式的,是能够赚到钱的,能够赚到钱才能聚集算力、聚集人才。
4、闭源在成本上反而是有优势的,只要是同等能力,闭源模型的推理成本一定是更低的,响应速度一定是更快的。
5、无论中美,当前最强的基础模型都是闭源的。通过基础模型降维做出来的模型也是更好的,这使得闭源在成本、效率上更有优势。
6、对于 AI 创业者来说,核心竞争力本就不应该是模型本身,这太耗资源了,而且需要非常长时间的坚持才能跑出来。
7、既做模型又做应用的“双轮驱动”,对创业公司不是好模式。创业公司的精力和资源都很有限,更应该专注。既做模型又做应用,势必会分散精力。
全文:https://www.pingwest.com/w/294047

5、福布斯发布 2024 年人工智能初创企业 50 强
斯坦福大学人工智能研究院发布《2024 年人工智能指数报告》
这份报告全面分析了 2023 年人工智能 (ai) 领域的进展,涵盖了技术进步、经济影响、政策制定和公众舆论等方面。
干货非常多,以下是报告的要点:
技术进步:
1、行业引领前沿 ai 研究:2023 年,行业贡献了 51 个重要的机器学习模型,而学术界仅贡献了 15 个。
2、基础模型崛起:2023 年发布了 149 个基础模型,是 2022 年的两倍多,其中 65.7% 是开源的。
3、前沿模型训练成本飙升:例如,openai 的 gpt-4 和 google 的 gemini ultra 的训练成本分别估计为 7800 万美元和 1.91 亿美元。
4、多模态 ai 兴起:新模型如 google 的 gemini 和 openai 的 gpt-4 能处理图像、文本甚至音频。
5、新的、更难的基准出现:研究人员开发了更具挑战性的基准来评估 ai 模型在更复杂任务上的能力。
经济影响:
1、生成式 ai 投资激增:尽管整体 ai 私人投资下降,但生成式 ai 领域的投资飙升至 252 亿美元。
2、美国在 ai 私人投资方面领先:2023 年,美国 ai 投资达到 672 亿美元,几乎是中国投资额的 8.7 倍。
3、ai 职位减少:美国和全球范围内对 ai 相关职位的需求均有所下降。
4、ai 提高效率:研究表明 ai 提高了员工的工作效率和工作质量。
5、财富 500 强公司谈论 ai:2023 年,近 80% 的财富 500 强公司在财报电话会议中提到了 ai。
政策制定:
1、美国 ai 法规数量大幅增加:2023 年,美国通过了 25 项与 ai 相关的法规,比 2016 年增加了一倍多。
2、美国和欧盟推进 ai 政策:欧盟就 ai 法案达成协议,美国总统拜登签署了关于 ai 的行政命令。
3、全球政策制定者关注 ai:2023 年,全球立法程序中对 ai 的提及数量几乎翻了一番。
公众舆论:
1、公众对 ai 的影响更加了解,也更加担忧:66% 的受访者认为 ai 将在未来三到五年内极大地影响他们的生活。
2、西方国家对 ai 的看法有所改善:尽管仍存在担忧,但对 ai 产品和服务的积极态度有所上升。
3、对 ai 经济影响的悲观看法:只有 37% 的受访者认为 ai 会改善他们的工作。
4、不同人群对 ai 的乐观程度存在差异:年轻一代对 ai 改善生活的潜力更为乐观。
5、chatgpt 广为人知:63% 的受访者知道 chatgpt,其中约一半的人每周至少使用一次。
其他重要发现:
1、ai 在科学和医学领域取得重大进展:ai 模型被用于加速药物发现、改进天气预报和创建更准确的人类基因组图谱。
2、负责任 ai 评估缺乏标准化:领先的 ai 开发人员使用不同的基准来评估其模型的责任风险,这使得比较变得困难。
3、政治深度伪造易于生成且难以检测:这引发了人们对 ai 对选举和政治进程的潜在影响的担忧。
4、ai 模型的训练会产生大量的碳排放:这引发了人们对 ai 可持续性的担忧。
完整的评选方法、专题报道和视频:http://forbes.com/ai50
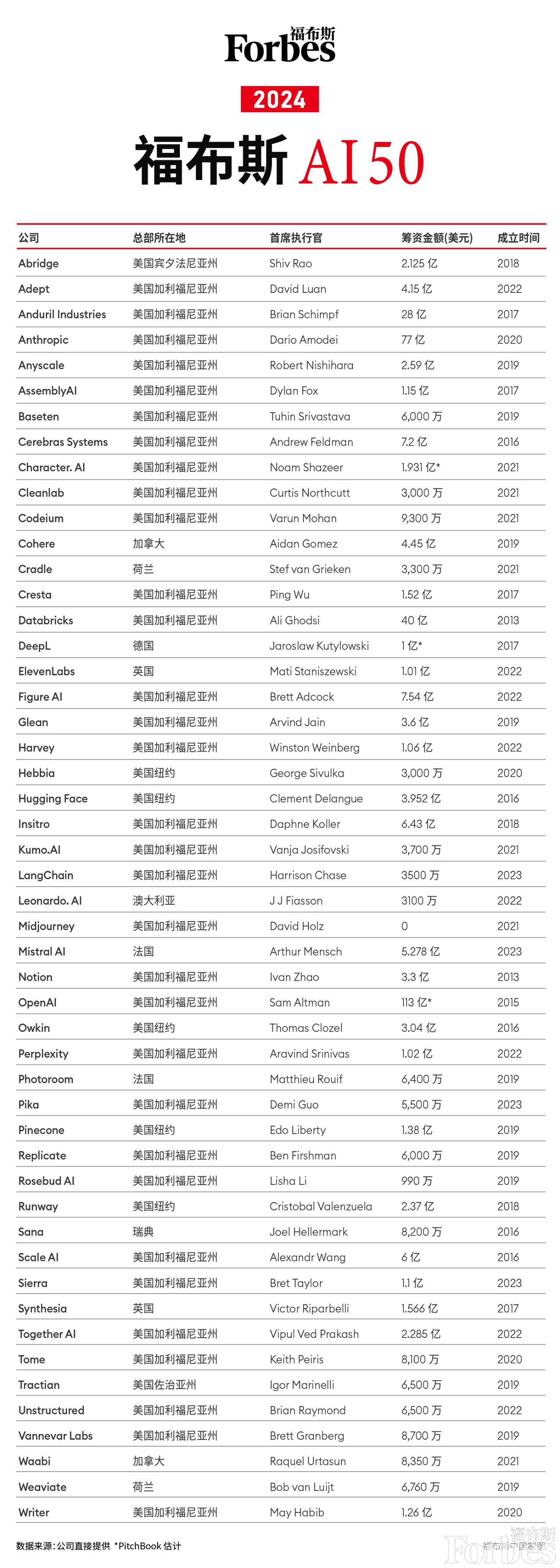 福布斯发布 ai 50 榜单 (2023):最有前途的人工智能公司
福布斯发布 ai 50 榜单 (2023):最有前途的人工智能公司
6、Ollama v0.1.32!重大发布:
💥 改进了 GPU 利用率和内存管理,以提高性能并降低错误率
💻 Mac 上的 Ollama 现在将在 GPU 和 CPU 之间调度更大的模型以提高性能
❤️ 更多错误修复和改进
⚡️ Ollama 现在在 @supabase Edge Functions 中提供原生 AI 支持
📚 支持更多型号:
🧙♂️ WizardLM 2,来自 Microsoft AI 的最先进的大型语言模型,在复杂聊天、多语言、推理和代理用例方面具有改进的性能。
🚤 在 Mistral 7B 上进行微调的快速、高性能模型推荐 8GB+ 显存)
🤓 在 Mixtral 8x22B 上微调的大型 8x22B 模型(推荐 96GB+ VRAM)
👇 👇 👇
https://github.com/ollama/ollama/releases
7、PyTorch 原生库 torchtune 的 alpha 版本发布!
torchtune 是一个 PyTorch 原生库,用于微调 LLMs。它将可破解的内存高效微调方法与你最喜欢的工具的集成相结合。
一个用于轻松微调 LLMs 的 PyTorch 原生库!
代码:https://github.com/pytorch/torchtune 博客:https://pytorch.org/blog/torchtune-fine-tune-llms/ 教程:https://pytorch.org/torchtune/stable/index.html#tutorials
- 精益、可扩展、无抽象的设计。没有训练器或框架,只有 PyTorch!
- 内存效率 - 我们在具有 24GB VRAM 的消费级 GPU 上测试我们的配方
- 与 PyTorch 生态系统中的流行库进行互操作
torchtune 提供:
- LLM 在本机 PyTorch 中的实现
- QLoRA、LoRA 和全面微调的配方
- 流行的数据集格式和 YAML 配置
- 与 @huggingface Hub、 @AiEleuther Eval Harness、bitsandbyes、ExecuTorch 等集成
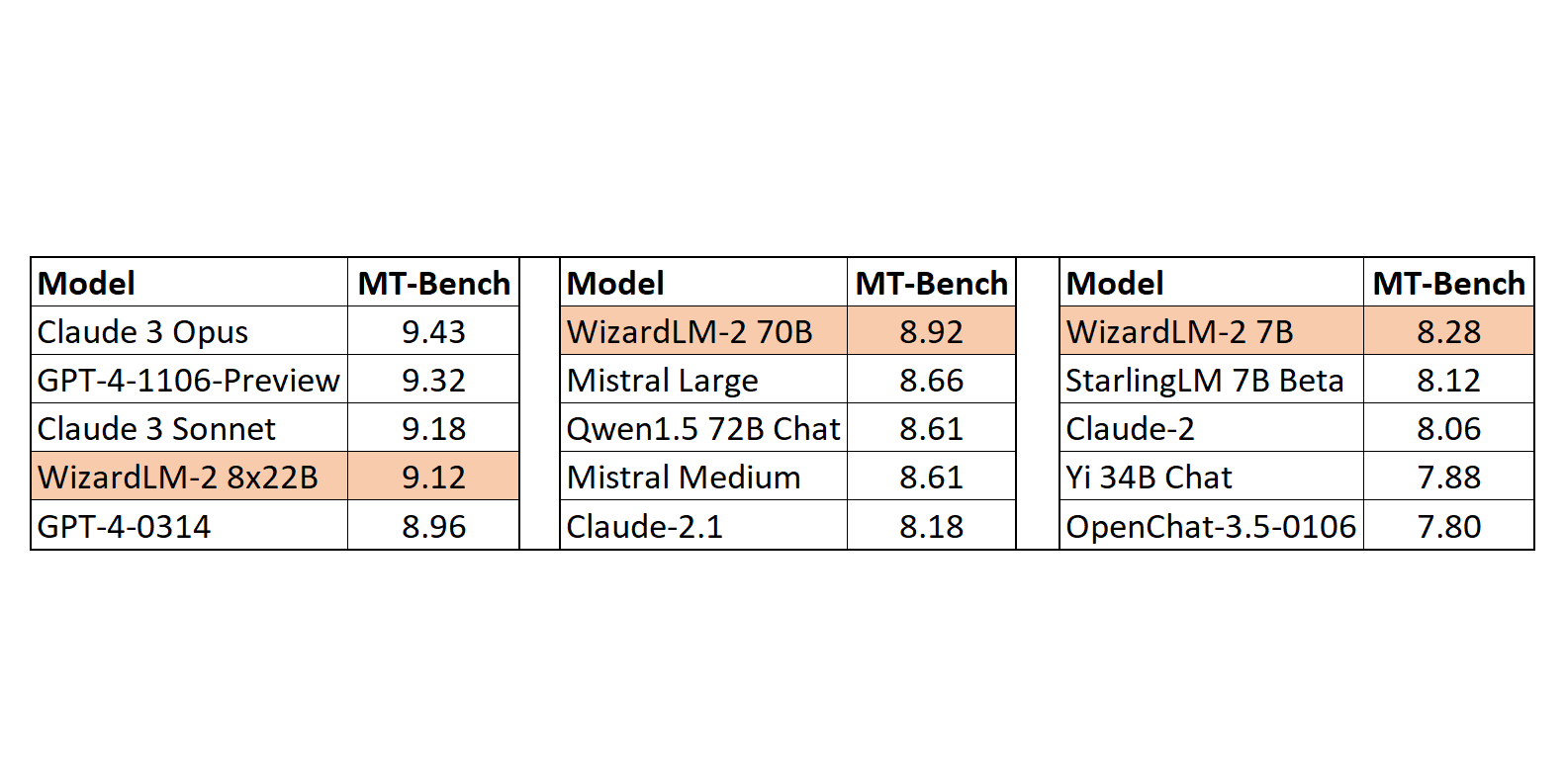
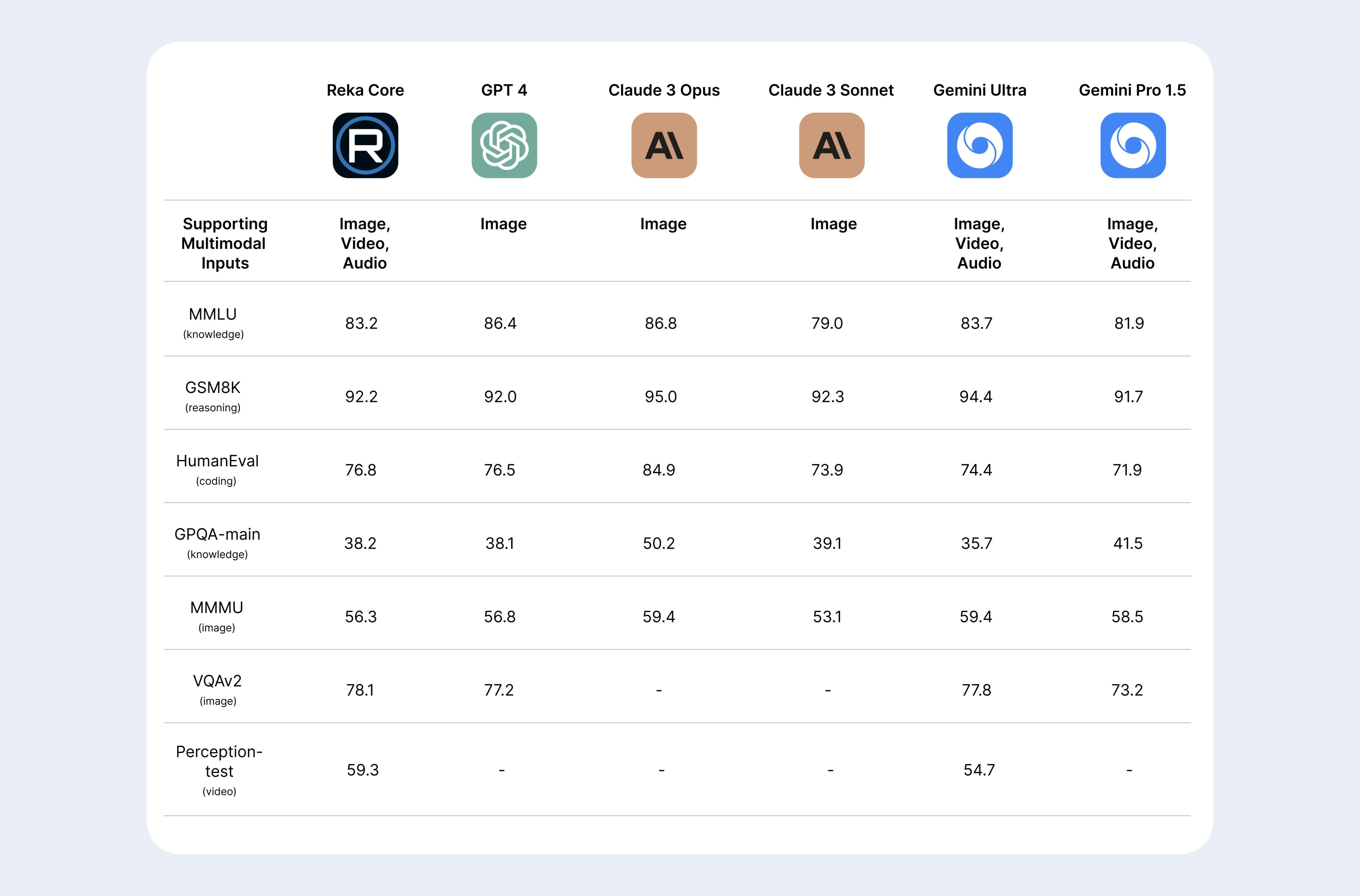
8、Reka Core:新的闭源多模态模型
像 Gemini 一样可以直接分析图片、视频、音频,评测得分与 GPT-4 和 Gemini-Ultra 接近。
在线使用:https://chat.reka.ai
官方博客:https://reka.ai/news/reka-core-our-frontier-class-multimodal-language-model
查了公司背景,一共 22 个员工,主要是 DeepMind 和 Google Brain 前成员
9、刘强东的数字人
4 月 16 日下午 6 时 18 分,由京东云言犀打造的“采销东哥”AI 数字人开启直播首秀,同时亮相京东家电家居、京东超市采销直播间。不到 1 小时,直播间观看量超 2000 万。
尽管是数字人,但“采销东哥”的语言贴近生活,言行之间还带有一些刘强东的标志性动作,人物形象生动、性格鲜明。
他谈笑自若,聊自己在运动、烹饪方面的心得,还对直播带货的大屏电视、一日三餐的健康搭配滔滔不绝。在数字人模仿抽奖互动场景,“采销东哥”时不时看下手机屏幕说:“看到你的留言了,回复了。”
据了解,言犀语音大模型在训练时,被“喂”入 5 万小时海量鲜活的语音数据,这让言犀数字人可以智能匹配不同直播风格,比如用沉稳的音色营造专业的氛围,又或者用极具感染力的声音吸引用户下单,还赋予姿态肢体表现。实验表明,绝大部分用户在 120 秒内难以察觉这是数字人。
起初“喂”给大模型的演讲素材,虽然充满激情、爆发力强,但过于正式。为此,他们用最新录制的闲谈作为主要素材,其中有刘强东本人的旅行经历,再提取 5 分钟演讲的韵律特征灌给大模型,通过不断优化,最终才塑造出“采销东哥”AI 数字人十分接近本人的声音。

